One of the first tasks that I was given in my job as a Data Scientist involved Web Scraping. This was a completely alien concept to me at the time, gathering data from websites using code, but is one of the most logical and easily accessible sources of data. After a few attempts, web scraping has become second nature to me and one of the many skills that I use almost daily.
In this tutorial I will go through a simple example of how to scrape a website to gather data on the top 100 companies in 2018 from Fast Track. Automating this process with a web scraper avoids manual data gathering, saves time and also allows you to have all the data on the companies in one structured file.
TL;DR For a quick example of a simple web scraper in python you can find the complete code as covered in this tutorial over on GitHub.
Getting Started
The first question to ask before getting started with any python application is ‘Which libraries do I need?’
For web scraping there are a few different libraries to consider, including:
- Beautiful Soup
- Requests
- Scrapy
- Selenium
In this example we will be using Beautiful Soup. Using pip, the Python package manager, you can install Beautiful Soup with the following:
pip install BeautifulSoup4
With these libraries installed, let’s get started!
Inspect the webpage
To know which elements that you need to target in your python code, you need to first inspect the web page.
To gather data from Tech Track Top 100 companies you can inspect the page by right clicking on the element of interest and select inspect. This brings up the HTML code where we can see the element that each field is contained within.
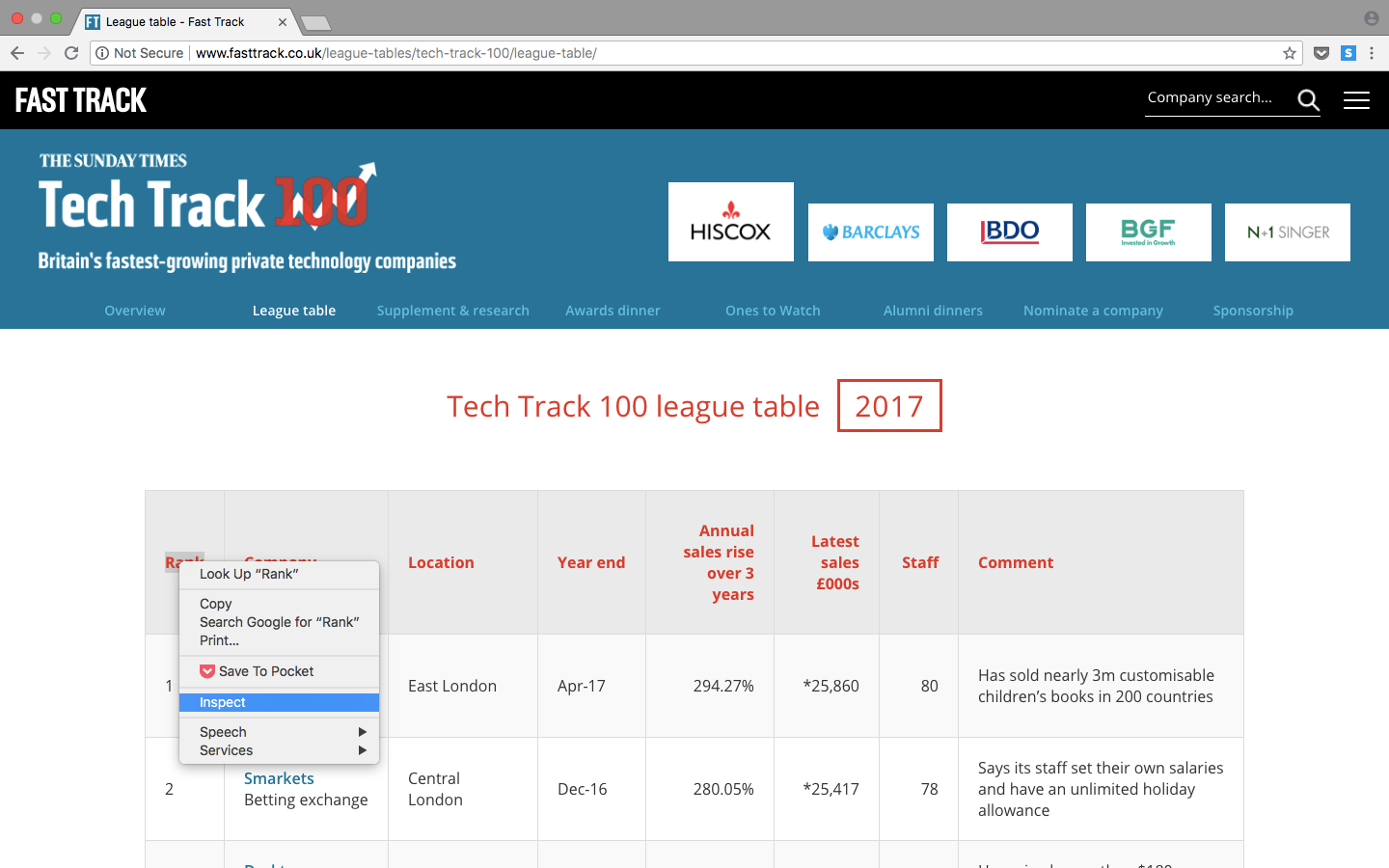
 Right click on the element you are interested in and select ‘Inspect’, this brings up the html elements
Right click on the element you are interested in and select ‘Inspect’, this brings up the html elements
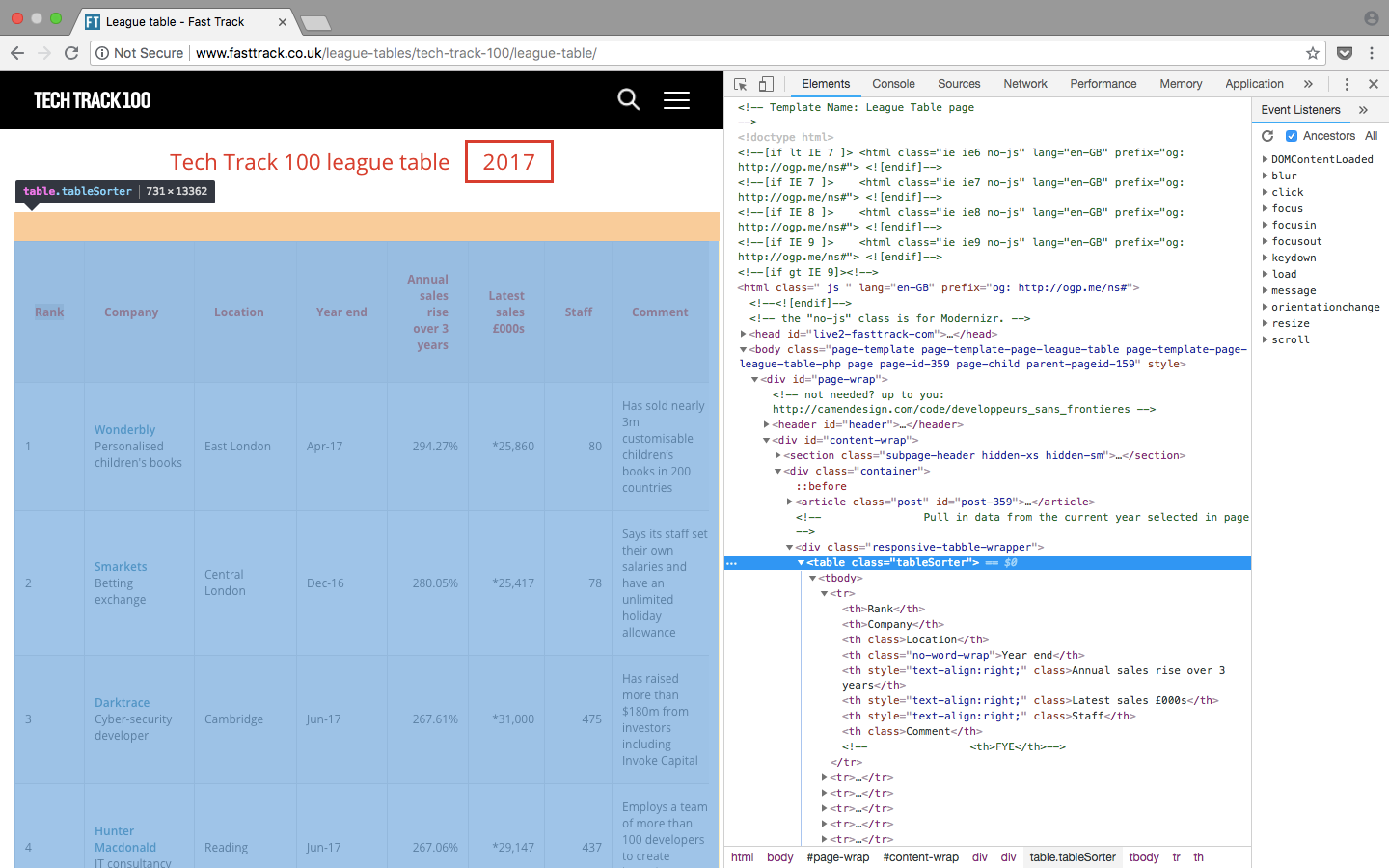
Since the data is stored in a table, it will be straight forward to scrape with just a few lines of code. This is a good example and a good place to start if you want to familiarise yourself with scraping websites, but bear in mind that it will not always be so simple!
All 100 results are contained within rows in <tr> elements and these are all visible on the one page. This will not always be the case and when results span over many pages you may need to either change the number of results displayed on a webpage, or loop over all pages to gather all the information.
On the League Table webpage, a table containing 100 results is displayed. When inspecting the page it is easy to see a pattern in the html. The results are contained in rows within the table:
<table class="tableSorter">
The repeated rows <tr> will keep our code minimal by using a loop within python to find the data and write to a file!
Side note: Another check that can be done is to check whether a HTTP GET request is being made on the website which may already return the results as structured response such as a JSON or XML format. You can check this from within the network tab in the inspect tools, often in the XHR tab. Once a page is refreshed it will display the requests as they are loaded and if the response contains a formatted structure, it is often easier to make a request using a REST Client such as Insomnia to return the output.
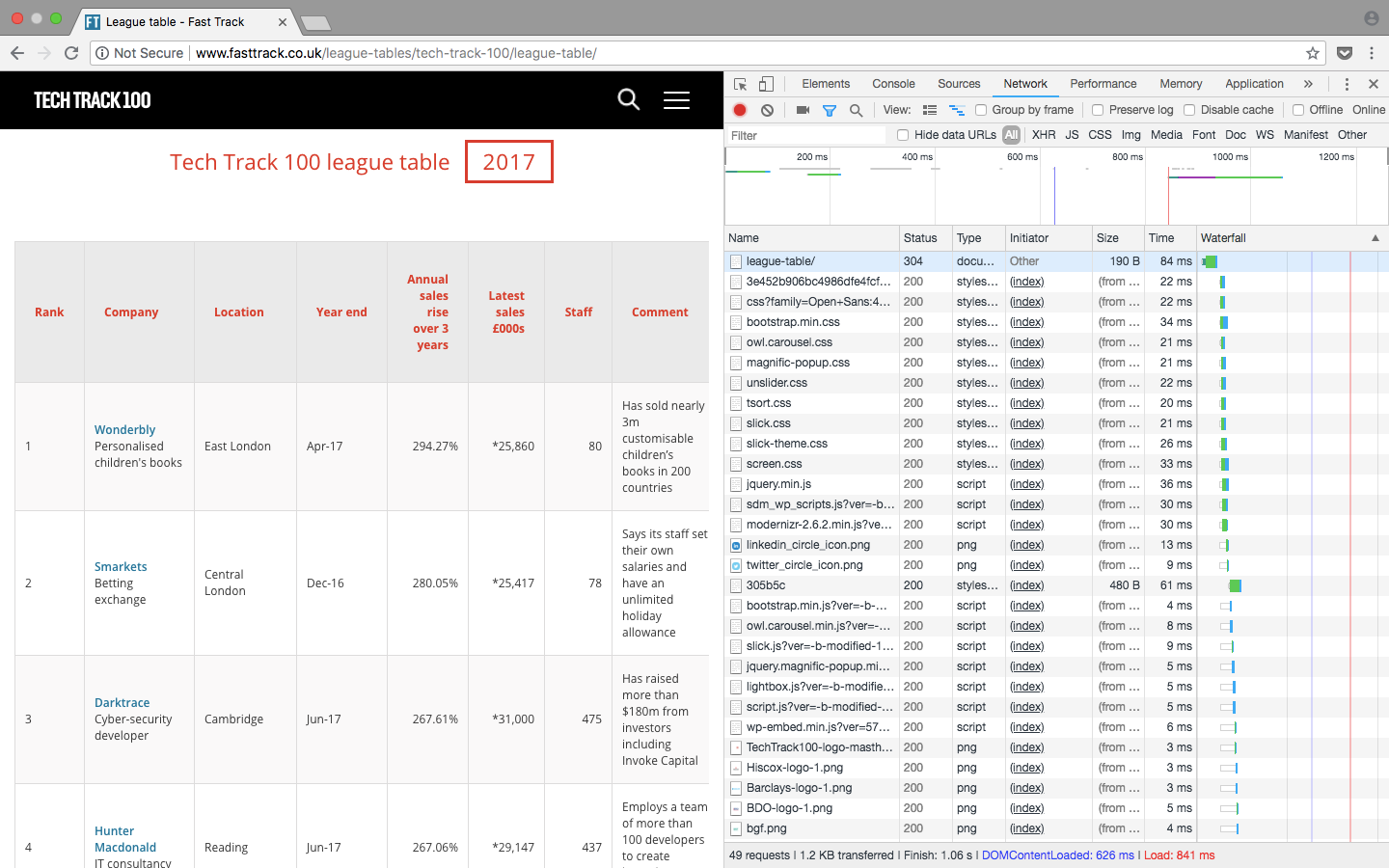 Network tab of the page inspect tool after refreshing the webpage
Network tab of the page inspect tool after refreshing the webpage
Parse the webpage html using Beautiful Soup
Now that you have looked at the structure of the html and familiarised yourself with what you are scraping, it’s time to get started with python!
The first step is to import the libraries that you will be using for your web scraper. We have already talked about BeautifulSoup above, which helps us to handle the html. The next library we are importing is urllib which makes the connection to the webpage. Finally, we will be writing the output to a csv so we also need to import the csv library. As an alternative, the json library could be used here instead.
# import libraries
from bs4 import BeautifulSoup
import urllib.request
import csv
The next step is to define the url that you are scraping. As discussed in the previous section, this webpage presents all results on one page so the full url as in the address bar is given here.
# specify the url
urlpage = 'http://www.fasttrack.co.uk/league-tables/tech-track-100/league-table/'
We then make the connection to the webpage and we can parse the html using BeautifulSoup, storing the object in the variable ‘soup’.
# query the website and return the html to the variable 'page'
page = urllib.request.urlopen(urlpage)
# parse the html using beautiful soup and store in variable 'soup'
soup = BeautifulSoup(page, 'html.parser')
We can print the soup variable at this stage which should return the full parsed html of the webpage we have requested.
print(soup)
If there is an error or the variable is empty, then the request may not have been successful. You may wish to implement error handling at this point using the urllib.error module.
Search for html elements
As all of the results are contained within a table, we can search the soup object for the table using the find method. We can then find each row within the table using the find_all method.
If we print the number of rows we should get a result of 101, the 100 rows plus the header.
# find results within table
table = soup.find('table', attrs={'class': 'tableSorter'})
results = table.find_all('tr')
print('Number of results', len(results))
We can therefore loop over the results to gather the data.
Printing the first 2 rows in the soup object, we can see that the structure of each row is:
<tr>
<th>Rank</th>
<th>Company</th>
<th class="">Location</th>
<th class="no-word-wrap">Year end</th>
<th class="" style="text-align:right;">Annual sales rise over 3 years</th>
<th class="" style="text-align:right;">Latest sales £000s</th>
<th class="" style="text-align:right;">Staff</th>
<th class="">Comment</th>
<!-- <th>FYE</th>-->
</tr>
<tr>
<td>1</td>
<td><a href="http://www.fasttrack.co.uk/company_profile/wonderbly-3/"><span class="company-name">Wonderbly</span></a>Personalised children's books</td>
<td>East London</td>
<td>Apr-17</td>
<td style="text-align:right;">294.27%</td>
<td style="text-align:right;">*25,860</td>
<td style="text-align:right;">80</td>
<td>Has sold nearly 3m customisable children’s books in 200 countries</td>
<!-- <td>Apr-17</td>-->
</tr>
There are 8 columns in the table containing: Rank, Company, Location, Year End, Annual Sales Rise, Latest Sales, Staff and Comments, all of which are interesting data that we can save.
This structure is consistent throughout all rows on the webpage (which may not always be the case for all websites!), and therefore we can again use the find_all method to assign each column to a variable that we can write to a csv or JSON by searching for the <td> element.
Looping through elements and saving variables
In python, it is useful to append the results to a list to then write the data to a file. We should declare the list and set the headers of the csv before the loop with the following:
# create and write headers to a list
rows = []
rows.append(['Rank', 'Company Name', 'Webpage', 'Description', 'Location', 'Year end', 'Annual sales rise over 3 years', 'Sales £000s', 'Staff', 'Comments'])
print(rows)
This will print out the first row that we have added to the list containing the headers.
You might notice that there are a few extra fields Webpage and Description which are not column names in the table, but if you take a closer look in the html from when we printed the soup variable above, the second row contains more than just the company name. We can use some further extraction to get this extra information.
The next step is to loop over the results, process the data and append to rows which can be written to a csv.
To find the results in the loop:
# loop over results
for result in results:
# find all columns per result
data = result.find_all('td')
# check that columns have data
if len(data) == 0:
continue
Since the first row in the table contains only the headers, we can skip this result, as shown above. It also does not contain any <td> elements so when searching for the element, nothing is returned. We can then check that only results containing data are processed by requiring the length of the data to be non-zero.
We can then start to process the data and save to variables.
# write columns to variables
rank = data[0].getText()
company = data[1].getText()
location = data[2].getText()
yearend = data[3].getText()
salesrise = data[4].getText()
sales = data[5].getText()
staff = data[6].getText()
comments = data[7].getText()
The above simply gets the text from each of the columns and saves to variables. Some of this data however needs further cleaning to remove unwanted characters or extract further information.
Data Cleaning
If we print out the variable company, the text not only contains the name of the company but also a description. If we then print out sales, it contains unwanted characters such as footnote symbols that would be useful to remove.
print('Company is', company)
# Company is WonderblyPersonalised children's books
print('Sales', sales)
# Sales *25,860
We would like to split company into the company name and the description which we can do in a few lines of code. Looking again at the html, for this column there is a element that contains only the company name. There is also a link in this column to another page on the website that has more detailed information about the company. We will be using this a little later!
<td><a href="http://www.fasttrack.co.uk/company_profile/wonderbly-3/"><span class="company-name">Wonderbly</span></a>Personalised children's books</td>
To separate company into two fields, we can use thefind method to save the element and then use either strip or replace to remove the company name from the company variable, so that it leaves only the description. To remove the unwanted characters from sales, we can again usestrip and replace methods!
# extract description from the name
companyname = data[1].find('span', attrs={'class':'company-name'}).getText()
description = company.replace(companyname, '')
# remove unwanted characters
sales = sales.strip('*').strip('†').replace(',','')
The last variable we would like to save is the company website. As discussed above, the second column contains a link to another page that has an overview of each company. Each company page has it’s own table, which most of the time contains the company website.
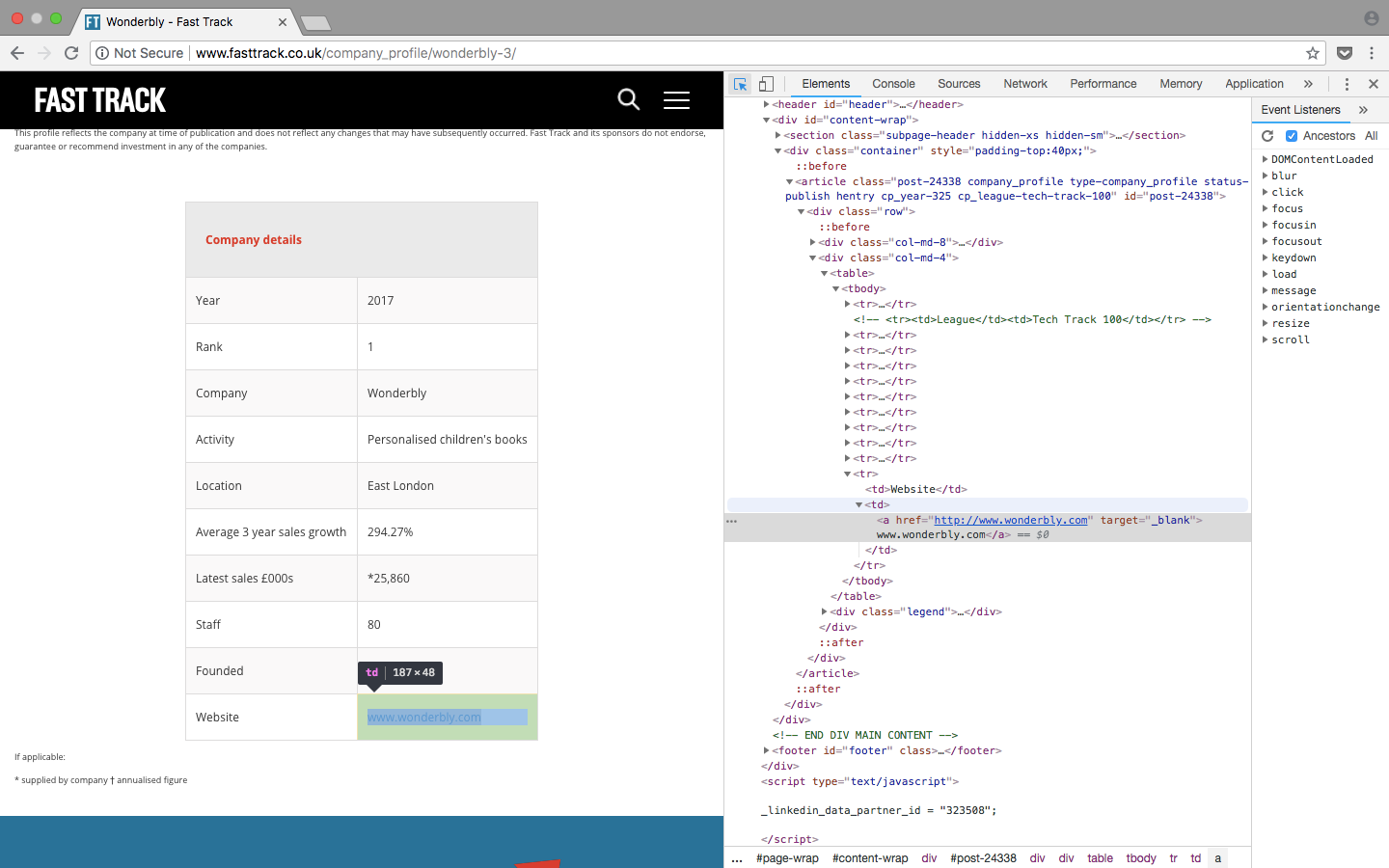 Inspecting the element of the url on the company page
Inspecting the element of the url on the company page
To scrape the url from each table and save it as a variable, we need to use the same steps as above:
-
Find the element that has the url of the the company page on the fast track website
-
Make a request to each company page url
-
Parse the html using Beautifulsoup
-
Find the elements of interest
Looking at a few of the company pages, as in the screenshot above, the urls are in last row in the table so we can search within the last row for the element.
# go to link and extract company website
url = data[1].find('a').get('href')
page = urllib.request.urlopen(url)
# parse the html
soup = BeautifulSoup(page, 'html.parser')
# find the last result in the table and get the link
try:
tableRow = soup.find('table').find_all('tr')[-1]
webpage = tableRow.find('a').get('href')
except:
webpage = None
There also may be cases where the company website is not displayed so we can use a try except condition, in case a url is not found.
Once we have saved all of the data to variables, still within the loop, we can add each result to the list rows.
# write each result to rows
rows.append([rank, companyname, webpage, description, location, yearend, salesrise, sales, staff, comments])
print(rows)
It is then useful to print the variable outside of the loop, to check that it looks as you expect before writing it to a file!
Writing to an output file
You may want to save this data for analysis and this can be done very simply within python from our list.
# Create csv and write rows to output file
with open('techtrack100.csv','w', newline='') as f_output:
csv_output = csv.writer(f_output)
csv_output.writerows(rows)
When running the python script your output file will be generated containing 100 rows of results that you can look at in further detail!
Summary
This brief tutorial on web scraping with python has outlined:
-
Connecting to a webpage
-
Parsing html using BeautifulSoup
-
Looping through the soup object to find elements
-
Performing some simple data cleaning
-
Writing data to a csv
This is my first tutorial so let me know if you have any questions or comments if things are not clear!
This article was originally published on Medium.

Kerry Parker
Data Engineer with PhD in Physics. Interested in all things data, personal development and productivity, see more posts on Medium.


